Foundations and Language Models
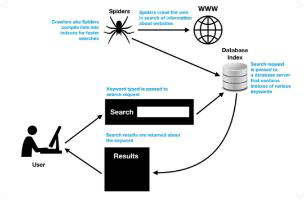
Probabilistic Information Retrieval
Foundations
Probabilistic Information Retrieval
- Motivation: Why Probability in IR?
- Contrast with Boolean & Vector Space Models
- Key Assumptions in Probabilistic IR
- Probability Basics
- Example: Probability of Relevance for a document
Probability Ranking Principle (PRP)
- Definition of PRP
- Intuition: Ranking by Probability of Relevance
- Case 1: 1/0 Loss Scenario
- Case 2: Incorporating Retrieval Costs
- Worked Example: PRP Applied to a Query
- Limitations of PRP
Binary Independence Model (BIM)
- Assumptions of BIM (Term Independence)
- Deriving Ranking Function –Step 1
- Deriving Ranking Function –Step 2
- Formula for Ranking Score (Log-Odds Weight)
- Probability Estimates in Theory
- Probability Estimates in Practice
- Example Calculation
- Relevance Feedback in Probabilistic Models
- Rocchio vs Probabilistic Feedback
- Strengths and Weaknesses of BIM
Extensions & Modern Models
- Appraisal of Probabilistic Models
- Tree-Structured Dependencies
- Okapi BM25: Motivation and Formula
- BM25 Example with Query/Document Scoring
- Bayesian Network (BN) Approaches to IR
- Summary of Probabilistic IR
Language Models for IR
- Definition of Language Models in IR
- Finite Automata and Language Models
- Types of Language Models
- Multinomial Distributions over Words
- Example: Unigram Language Model
Query Likelihood Model
- Query Likelihood Principle
- Using Query Likelihood in IR
- Estimating Query Generation Probability
- Maximum Likelihood Estimation (MLE)
- Smoothing Techniques
- Ponte & Croft’s Experiments –Setup
- Ponte & Croft’s Experiments –Results
- Lessons Learned from Query Likelihood
Comparisons & Extensions
- Language Modelling vs Probabilistic IR
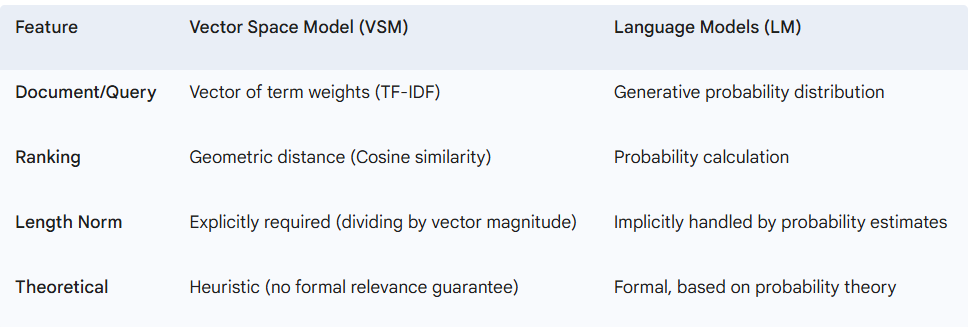
- Language Modelling vs VSM
- Strengths of LM Approaches
- Weaknesses of LM Approaches
- Extended LM Approaches: Mixture Models
- Topic Models (e.g., LDA) in IR
- Neural Language Models in Modern IR (Word Embeddings, Transformers)
- Example: BERT in Document Ranking
Wrap-Up
- Summary: Probabilistic vs Language Models
- Implications for Web Search
Probabilistic Information Retrieval
Motivation: Why Probability in IR?

Contrast with Boolean & Vector Space Models
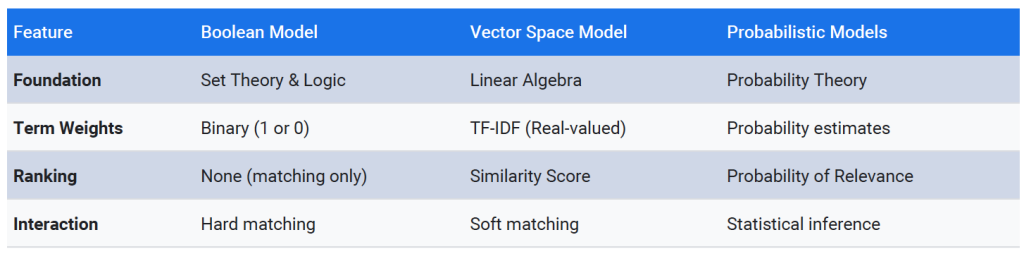
Key Assumptions in Probabilistic IR

Probability Basics

Example: Probability of Relevance for a document

Probability Ranking Principle (PRP)
Definition of PRP
- Core Principle: If a retrieval system’s goal is to maximize the overall utility (or minimize the expected loss) of the retrieved set, then the documents should be ranked in order of decreasing probability of relevance.
- Formal Statement: For a document d, rank d1 above d2 if and only if: P(R=1 |d1) > P(R=1 |d2)
- History:
- The Probability Ranking Principle (PRP) was introduced by Stephen E. Robertson in 1977 as a foundational concept in information retrieval (IR), asserting that documents should be ranked by their probability of relevance to a query.
Intuition: Ranking by Probability of Relevance
- Simple Logic
- If you have to choose between Document A (80% chance of being helpful) and Document B (50% chance of being helpful), you should always choose A first.
- Optimal Performance
- A ranking based on the Probability Ranking Principle is mathematically proven to be the optimalranking for a given set of relevance judgments and probability estimates.
- ✅Why It’s Optimal
- It minimizes the chance of showing irrelevant documents first—meaning users will see the most relevant documents first.
- It maximizes precision at every rank position.
- It aligns perfectly with how users judge search quality —they want the most useful results first.
- Focus
- The complexity lies not in the ranking rule, but in accurately estimating the probability P(R=1|d)
Case 1: 1/0 Loss Scenario

Case 2: Incorporating Retrieval Costs

Worked Example: PRP Applied to a Query
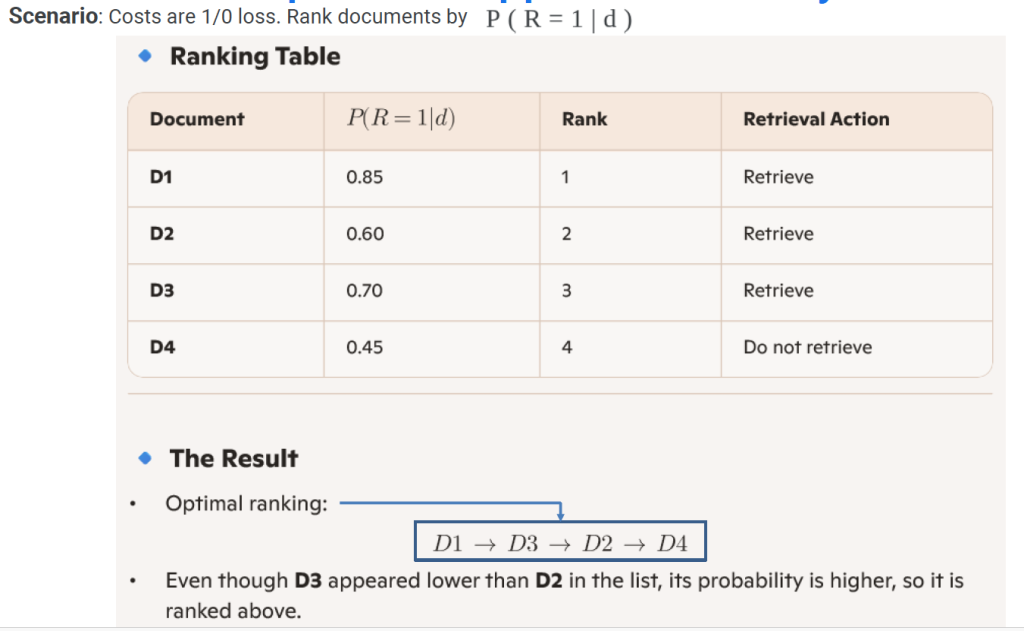
Limitations of PRP

Binary Independence Model (BIM)
Assumptions of BIM (Term Independence)

Deriving Ranking Function –Step 1

Deriving Ranking Function –Step 2

Formula for Ranking Score (Log-Odds Weight)

Probability Estimates in Theory

Probability Estimates in Practice

Example Calculation

Relevance Feedback in Probabilistic Models

Rocchio vs Probabilistic Feedback

Strengths and Weaknesses of BIM

Extensions & Modern Models
Appraisal of Probabilistic Models

Tree-Structured Dependencies

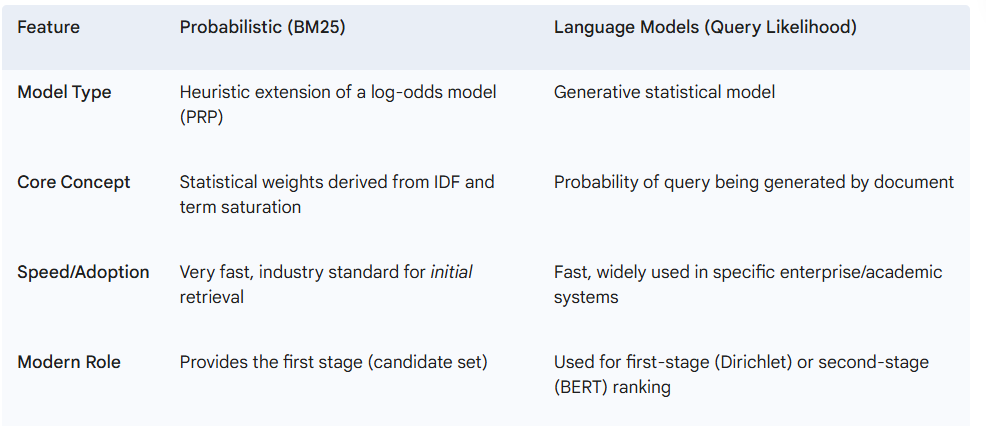
Okapi BM25: Motivation and Formula

BM25 Example with Query/Document Scoring

Bayesian Network (BN) Approaches to IR

Summary of Probabilistic IR

Language Models for IR
Definition of Language Models in IR

Finite Automata and Language Models

Types of Language Models

Multinomial Distributions over Words

Example: Unigram Language Model

Query Likelihood Model
Query Likelihood Principle

Using Query Likelihood in IR

Estimating Query Generation Probability

Maximum Likelihood Estimation (MLE)

Smoothing Techniques

Ponte & Croft’s Experiments –Setup

Ponte & Croft’s Experiments –Results

Lessons Learned from Query Likelihood

Comparisons & Extensions
Language Modelling vs Probabilistic IR
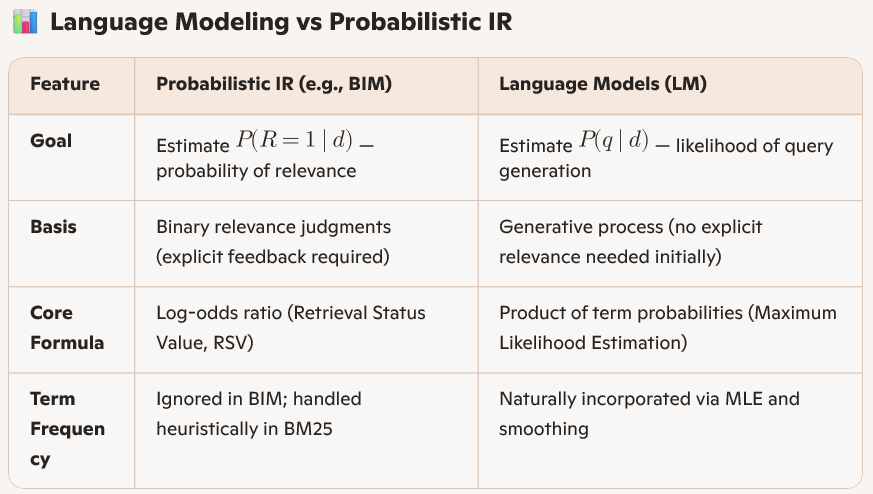
Language Modelling vs VSM
Strengths of LM Approaches

Weaknesses of LM Approaches

Extended LM Approaches: Mixture Models

Topic Models (e.g., LDA) in IR

Neural Language Models in Modern IR (Word Embeddings, Transformers)

Neural Language Models in Modern IR (Word Embeddings, Transformers)
Example: BERT in Document Ranking

Wrap-Up
Summary: Probabilistic vs Language Models
Implications for Web Search

Watch, Read, Listen
Join 900+ subscribers
Stay in the loop with everything you need to know.